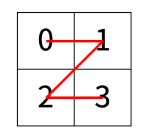
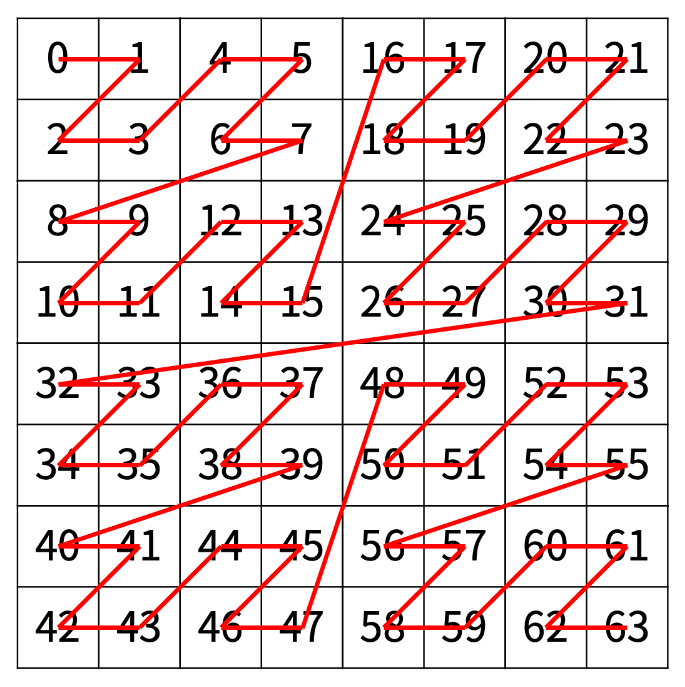
한수는 크기가 2N × 2N인 2차원 배열을 Z모양으로 탐색하려고 한다. 예를 들어, 2×2배열을 왼쪽 위칸, 오른쪽 위칸, 왼쪽 아래칸, 오른쪽 아래칸 순서대로 방문하면 Z모양이다. N > 1인 경우, 배열을 크기가 2N-1 × 2N-1로 4등분 한 후에 재귀적으로 순서대로 방문한다. 다음 예는 22 × 22 크기의 배열을 방문한 순서이다. N이 주어졌을 때, r행 c열을 몇 번째로 방문하는지 출력하는 프로그램을 작성하시오. 다음은 N=3일 때의 예이다. [입력] 첫째 줄에 정수 N, r, c가 주어진다.
[출력] r행 c열을 몇 번째로 방문했는지 출력한다.
✅ 문제 풀이
분할과 정복 파트에 있는 문제이다.
하지만 흔히 푸는 방식인 재귀함수 호출을 이용한다면, 테스트 케이스는 통과할지 몰라도, 시간초과 또는 메모리 초과가 발생할 것이다.
일단 메모리 초과가 나는 이유는, 배열을 선언하고 저장하는 형태로 접근해서 일 것이다.
입력을 보면 우리는 최대 2^30 크기의 배열이 필요하게 되기 때문에, 기가 수준의 메모리가 필요해진다.
사실상, 주어진 입력을 통해 배열을 굳이 선언하지 않고도 단순히 카운트한 값만을 이용할 수 있으니, 배열은 필요없다 -> 메모리초과 문제 해결
두번째는 시간 초과인데, 입력이 커지면, 굳이 필요없는 방문이 반복적으로 발생하게 된다. 즉 너무나 깊은 함수 호출로 인해 오히려 시간초과가 발생하는 것이다.
그럼 재귀호출 말고, 단순히 반복문으로 쉽게 카운트 하는 방법을 찾을 수 있다.
나는 다음과 같은 규칙을 찾아냈다.
1. 주어진 (r,c)의 번호는 이전에 이 영역에 도달하기 전에 크기가 1인 몇개의 영역을 지나왔는가와 동일하다.
예를 들어, 2*2크기의 배열이 있다고 할때, (1,1)에 도달 하기 전에는 (0,0),(0,1),(1,0)순으로 3개를 거친후 도달한다.
따라서 (1,1)의 번호는 3으로 매겨질 수 있는 것이다.
2. 주어진 (r,c)의 영역 범위와, 배열 크기에 따라 이전에 몇개를 거쳐오는지를 통채로 빠르게 계산할수 있다.
예를 들어 4*4 크기의 배열이 있다고 할때, (3,3)의 번호를 구하고 싶다고 하자.
이 위치는 배열을 4등분 했을 때, 방문 순서로 따지면 4번째 영역에 존재한다. 따라서 3번째 영역을 다 돌고 난 후의 값보다는 무조건 클 것이다.
그러므로 굳이 현재 (3,3)이 존재하는 4번째 영역을 제외하고는 일일이 탐색할 필요없이, 그 크기만큼 count에 더해주면 된다.
따라서 한 영역당 크기가 4이므로, 네번째 영역이라면, 4*3=12보다는 무조건 큰 번호를 가지게 된다.
이렇게 12를 count에 더해주고, 이제 네번째 영역을 하나의 배열이라 치고 위의 과정을 반복하면 된다.
이어서 설명하자면, 네번째 영역을 하나의 배열이라 치면 크기가 4인 배열이고, 여기서 (3,3)은 이 배열을 또 4등분 했을때 4번째 영역에 속하는 것이기 때문에, 한 영역당 크기가 1이므로, 1*3=3을 count에 더해주면 된다. 이제 (3,3)은 크기가 1인 배열이므로 더이상 쪼개지지 않고, 현재의 count 값인 15가 답이 되는 것이다.
✏ 코드 전문
#include<iostream>
#include<vector>
#include<math.h>
using namespace std;
void divide(int x, int y, int size, int &count, int &r, int&c) {
while (size >= 1) {
int set = pow(size / 2, 2);
if (r < x + size / 2 && c < y + size / 2) {
}
else if (r < x + size / 2 && c >= y + size / 2 && c < y + size) {
count += set;
y += size / 2;
}
else if (r >= x + size / 2 && r < x + size && c < y + size / 2) {
count += set * 2;
x += size / 2;
}
else {
count += set * 3;
x += size / 2;
y += size / 2;
}
size /= 2;
}
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N, r, c;
cin >> N >> r >> c;
int size = pow(2, N);//처음 행,열의 크기
int count = 0;
divide(0, 0, size, count, r, c);
cout << count;
}
코드로 표현하자면 다음과 같이 접근했다.
size를 배열의 한 변 길이로 두고, 그 배열에서 가장 처음 방문하는 곳을 x와 y로 두었다 .
배열의 한변 길이가 1이 될 때까지, 즉 계속해서 쪼개지는 배열이 하나의 요소가 될때까지 ,쪼개면서 count하도록 하였다.-> 분할과 정복
set는 현재 배열에서 4등분 했을 때 각 영역의 크기를 저장한다.
이제 4개의 영역마다 서로 다른 로직을 따르도록 할것이다.
만약 (r,c)가 1번 영역에 속한다면 = 1번 영역은 배열 시작인 x,y각각에 size/2를 더한 것의 내부에 존재하는 영역이다. 그렇다면 처음 방문인 거니까 x, y도 기준 그대로 이고, 이전 방문 내역이 없으므로 count하지 않아도 된다.
만약 (r,c)가 2번 영역에 속한다면 = 2번 영역은 배열 시작인 x에 size/2를 더한 것의 내부이면서, y는 size/2를 더한것의 이상이고 size를 더한 것보다는 작은 영역이다. 그렇다면 이전에 1번 영역을 방문한 거니까, count에는 set만큼 더해주고, y의 기준을 size/2만큼 더해주어서 갱신해준다. 이 부분이 다음 단계에서는 첫 방문이 되도록 하기 위함이다.
만약 (r,c)가 3번 영역에 속한다면 = 3번 영역은 배열 시작인 x에 size/2를 더한것의 이상이면서 size를 더한것보다는 작은 영역이고, y에 size/2를 더한 것보다는 작은 영역이다. 그렇다면 이전에 1번과 2번 영역을 방문한 거니까, count에는 set*2만큼 더해주고, x의 기준을 size/2만큼 더해주어서 갱신해준다. 이 부분이 다음 단계에서는 첫 방문이 되도록 하기 위함이다.
만약 (r,c)가 4번 영역에 속한다면 = 4번 영역은 배열 시작인 x에 size/2를 더한것의 이상이면서 size를 더한것보다는 작은 영역이고, y에 size/2를 더한 것의 이상이면서 size를 더한것보다는 작은 영역이다. 그렇다면 이전에 1번과 2번과 3번 영역을 방문한 거니까, count에는 set*3만큼 더해주고, x의 기준을 size/2만큼, y의 기준을 size/2만큼 더해주어서 갱신해준다. 이 부분이 다음 단계에서는 첫 방문이 되도록 하기 위함이다.