반응형
https://www.acmicpc.net/problem/7569
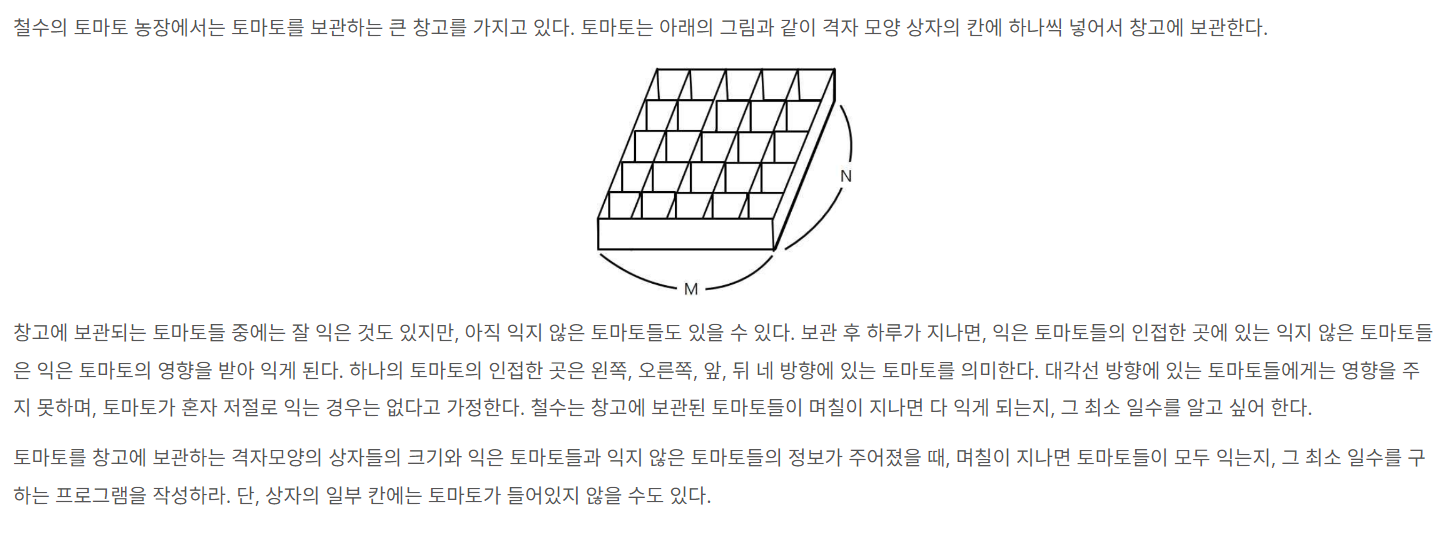
7569번: 토마토
첫 줄에는 상자의 크기를 나타내는 두 정수 M,N과 쌓아올려지는 상자의 수를 나타내는 H가 주어진다. M은 상자의 가로 칸의 수, N은 상자의 세로 칸의 수를 나타낸다. 단, 2 ≤ M ≤ 100, 2 ≤ N ≤ 100,
www.acmicpc.net
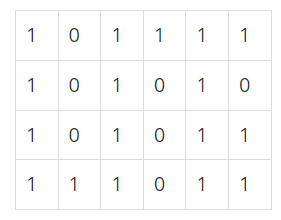
토마토 2차원 배열 입력 문제 풀이 참고
2024.01.22 - [CO-TE/백준] - [백준] 7576번 C++ "토마토" 풀이 / BFS, 너비우선탐색
[백준] 7576번 C++ "토마토" 풀이 / BFS, 너비우선탐색
https://www.acmicpc.net/problem/7576 7576번: 토마토 첫 줄에는 상자의 크기를 나타내는 두 정수 M,N이 주어진다. M은 상자의 가로 칸의 수, N은 상자의 세로 칸의 수를 나타낸다. 단, 2 ≤ M,N ≤ 1,000 이다. 둘
im-gonna.tistory.com
💡 토마토(3차원 배열 입력 ver.)


✅ 문제 풀이
- 이전에 풀었던 토마토 (7576번) 문제와 풀이 방식은 동일한데, 입력으로 주어지는 차원이 3차원으로 늘어나 높이까지 고려해야 한다.
- 따라서 입력을 받는 arr 벡터도 3차원으로 정의해주었고, 좌표를 담는 queue의 자료형도 pair를 한번 더 감싸서 3개의 int 쌍을 갖도록 하였다.
=> pair<pair<int,int>,int> - 입력으로는 한 판 씩 맨 아래 층 부터 들어오기 때문에 for문의 시작에 for문을 하나 더 추가해서 높이마다 한판 씩 정보를 입력 받도록 하였다.
= 마지막에 확인할 때도 맨앞에 높이에 대한 for문만 추가해주었다. - queue에 push할때도 queue의 자료형에 맞게 두 개의 pair 쌍으로 값을 입력해주었다. 여기서 x 와 y 는 전체 pair에서도 첫번째인 pair 쌍에 해당하기 때문에 front().first.first, front().first.second 로 두번씩 들어가 접근하도록 하였고, z는 전체 pair에서 두번째 값이기 때문에 front().second로 접근하도록 하였다.
- 높이에 대한 조건이 추가되면서, 인접한 범위가 위, 아래 까지 늘어났다. 따라서 총 6번의 탐색을 해야하므로, bfs 함수내에서 사용하는 dx, dy를 수정해주었다. 맨뒤에 높이에 대한 변화가 없도록 {0,0}을 추가해준다. 그리고 높이에 대한 dz를 추가해주고, {0,0,0,0,-1,1} 으로 높이에 대해서만 변화가 있도록 한다.
- bfs 함수 내에서 탐색은 4->6으로 수정해주고, 함수의 인자로는 x,y 뿐만 아니라, z도 받도록 하여, 전체 위치를 표시해준다.
- arr의 인덱스 범위에서도 z는 0이상 h이하에 있도록 검사한다.
- 나머지 로직은 동일하다.
✏ 코드 전문
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
int n, m, h;
vector<vector<vector<int>>> arr;
queue<pair<pair<int, int>,int>> q;
queue<pair<pair<int, int>,int>> temp;
int dx[] = { -1,1,0,0,0,0 };
int dy[] = { 0,0,-1,1,0,0 };
int dz[] = { 0,0,0,0,-1,1 };
int answer = 0;
void bfs(int x, int y, int z) {
for (int i = 0; i < 6; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
int nz = z + dz[i];
if (nx >= 0 && nx < n&&ny >= 0 && ny < m&& nz>=0 && nz< h&& arr[nx][ny][nz] == 0) {
arr[nx][ny][nz] = 1;
temp.push(pair<pair<int, int>, int> (pair<int, int>(nx, ny),nz));
}
}
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cin >> m >> n >> h;
arr.resize(n, vector<vector<int>>(m, vector<int> (h)));
for (int k = 0; k < h; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> arr[i][j][k];
if (arr[i][j][k] == 1) {
q.push(pair<pair<int, int>, int> (pair<int, int> (i, j), k));
}
}
}
}
while (!q.empty()) {
bfs(q.front().first.first, q.front().first.second, q.front().second);
q.pop();
if (q.empty()) {//한번 돌았음을 의미
answer++;
while (!temp.empty()) {
q.push(pair<pair<int, int>, int> (pair<int, int> (temp.front().first.first, temp.front().first.second),temp.front().second));
temp.pop();
}
}
}
for (int k = 0; k < h; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (arr[i][j][k] == 0) {
cout << -1;
return 0;
}
}
}
}
cout << answer - 1;
return 0;
}반응형
'CO-TE > 백준' 카테고리의 다른 글
| [백준] 15686번 C++ "치킨 배달" 풀이 / 완전 탐색, 조합 / 삼성 sw역량테스트 기출문제 (1) | 2024.02.02 |
|---|---|
| [백준] 9251번 C++ "LCS" 풀이 / DP (1) | 2024.01.31 |
| [백준] 10026번 C++ "적록색약" 풀이 / dfs, 너비 우선 탐색 (0) | 2024.01.27 |
| [백준] 2447번 C++ "별 찍기 -10" 풀이 / 재귀, 분할정복, 프렉탈 (0) | 2024.01.24 |
| [백준] 11729번 C++ "하노이 탑 이동 순서" 풀이 / 재귀호출 (1) | 2024.01.23 |