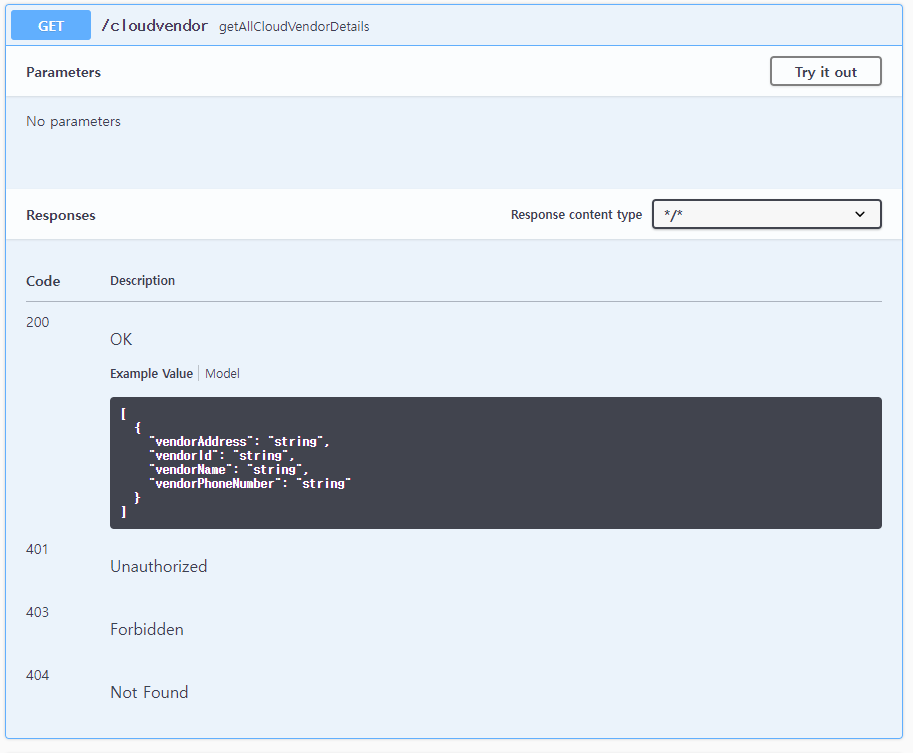
이 코드는 yml파일에서 Spring MVC 프레임워크의 경로 매칭 전략을 지정하는 데 사용된다.
이 설정은 경로 매칭 전략을 ant_path_matcher로 설정한 것인데, spring의 ant 스타일의 경로 패턴 매칭 전략을 사용한다는 것을 의미한다.
이러한 mvc 경로 매칭은 URL과 컨트롤러 메소드 사이의 매핑을 결정하는 프로세스이다.
사용자가 특정 URL로 요청을 보내면, spring mvc는 해당 요청을 어떤 컨트롤러 메소드와 매핑할지를 결정하고 실행한다.
ant 스타일의 경로 패턴은 와일드카드(*)를 사용해서 유연한 경로 매칭을 가능하게 하는데, 이를 이용해서 URL을 매칭한다.
예를 들어서 /cloudvendor/*는 /cloudvendor/ 또는 /cloudvendor/c5 와같은 URL과 일치할 수 있다.
따라서 해당 URL과 일치하는 메소드를 매핑하게 된다.
위와 같이 swagger를 사용할 준비가 되었으면, spring boot를 실행해본다.
실행하면 api 문서도 자동으로 만들어진다.
8080 포트에서 성공적으로 연결되었다.
💡 POST MAN에서 api 문서 생성 확인
post man에서 실행 후 생성된 api document를 확인해보자.
일단 post를 통해 C5를 생성해보자. 완료
get을 통해 C5를 검색하고 읽어보자. 완료
새로운 get request를 만들어서 경로를 http://localhost:8080/v3/api-docs 로 지정해주면, 문서를 읽을 수 있다.
여기서 v3은 version 3라는 뜻. 우리는 3.0.0을 사용하기 때문에! (2.x이면 v2)
이 request의 이름은 Swagger document라고 지정해주자.
send를 누르니, 아래와 같은 response가 출력되었다.
openapi의 버전은 3.0.3
생성된 api 문서의 title은 Api Documentation이고, 그 아래와 같은 내용으로 문서가 구성되어 있다.
💡 swagger-ui
위와 같이 확인하니 잘 와닿지 않는다.
그런데 Swagger는 사용자에게 편리한 UI 페이지를 제공하여 문서를 확인할 수 있게한다.
그게 바로 swagger-ui이다.
http://localhost:8080/swagger-ui/ 이 링크를 웹에 입력하여 확인해보자.
swagger-ui 페이지를 보니, postman에서 response에 있던 내용들로 문서가 시각적으로 제공되고있음을 확인할 수 있다.
api document url
이렇게 swagger가 자동 생성해준 문서 내용을 내가 커스텀해서 수정할 수도 있다.
현재는 너무 일반적인 정보뿐이고, cloud vendor api의 특성에 맞게 디테일한 것을 추가하고 수정할 수 있다.
basic-error-controller(패키지 정보)를 지우고, api의 주된 controller 내용만 보이게 하며, api 정보도 cloud vendor로 변경해보려 한다.
💡 api 문서 커스텀하기
spring boot application이 시작되는 지점에다가 docket bean을 생성함으로써 커스텀을 진행할 수 있다.
docket이란?
docket은 swagger를 사용하여 api 문서를 생성하기 위한 설정 클래스로, api 문서의 어떤 정보를 어떻게 표시할지 등을 설정해주기 위한 용도이다.
즉, 실행 컨트롤러 클래스 하에 아래 코드를 추가해준다.
@Beanpublic Docket swaggerConfiguration(){
returnnew Docket(DocumentationType.SWAGGER_2)
.select()
.paths(PathSelectors.ant("/cloudvendor/*"))
.apis(RequestHandlerSelectors.basePackage("com.mstoy.restdemo"))//패키지를 그대로
.build()
.apiInfo(apiCustomData()); //인자로 ApiInfo를 주어야 함, 아래에서 하나 생성해주고 넣어줄것임
}
private ApiInfo apiCustomData(){//여기다가 costom 파라미터들을 설정해주면 됨returnnew ApiInfo(
"Cloud Vendor API Application",
"Cloud Vendor Documentation",
"1.0",
"Cloud Vendor Service Terms",
new Contact("Minseo Kim", "https://github.com/minseo0102",
"sk49058275@gmail.com"),
"Minseo 0102 License",
"https://github.com/minseo0102",
Collections.emptyList()
);
}
public Docket swaggerConfiguration() - Docket을 반환하는 swaggerConfiguration 함수를 정의한다. - Docket을 반환하기 때문에 Docket 객체를 동적 할당해준뒤, return한다. - 인자로는 문서 타입을 넣어주는데, swagger2로 한다. - yml 파일에서 우리는 ant 스타일의 경로 패턴을 사용하기로 했기때문에, 경로 paths는 "/cloudvendor/*"로 설정하여 cloudvendorController에 있는 모든 crud 메서드와 매핑되도록 한다. - apis(RequestHandlerSelectors.basePackage("com.mstoy.restdemo"))를 통해 해당 패키지에 속한 컨트롤러만 문서화 하도록 해서 basic-error-controller가 뜨지 않도록 하였다. - api 문서의 내용을 커스텀하기 위해서 apiInfo에 내가 설정해준 내용을 담아야 하는데, 이는 ApiInfo라는 객체에 담아서 인자로 전달할 수 있다. 따라서 아래 private으로 ApiInfo 객체를 반환하는 메서드 apiCustomData()를 만들어 주었다.
private ApiInfo apiCustomData() - ApiInfo 객체를 동적 할당하여 반환하도록 하고, 인자로 커스텀할 정보를 담아준다. - 어떤 인자들을 담을 수 있는지는 ApiInfo 클래스를 참고하여 확인할 수 있다. - title(string), description(string), version(string), termsOfServiceUrl(string), contact(Contact), license(string), licenseUrl(string), vencorExtentions(collection) 총 8개의 파라미터가 있다. - title : api 문서의 제목이다. 프로젝트 또는 api의 이름이 여기에 들어간다. cloudvendor api이므로 "Cloud Vendor API Application"로 설정해주었다. - description : api 문서에 대한 간단한 설명이다. api의 목적이나 주요 기능을 적어준다. - version : api의 현재 버전이다. 변경될때마다 버전을 높혀줄 수 있다. 1.0을 시작으로 한다. - termsOfServiceUrl : 서비스 이용 약관의 URL을 지정한다. api 사용자에게 약관을 제공하고자 할때 활용한다. - contact : api에 대한 연락처이다. 담당자 이름, 이메일, 웹사이트를 제공한다. 내 이름과, 이메일, 깃허브 주소를 적었다. - license : api의 라이센스 정보다. - licenseUrl : 라이센스에 대한 url이다. 라이센스에 대한 자세한 정보를 사용자에게 제공할 때 활용한다. 내 깃허브 주소를 적어주었다. - vendorExtensions : swagger 명세에서 제공하는 기능 외 추가적인 속성을 지정할 때 사용한다. 그냥 빈 collection으로 넣어주었다.
커스텀 할 apiInfo에 대해서는 인자로 ApiInfo를 넣어주어야 하기 때문에, private으로 ApiInfo 객체를 반환하는 메서드를 선언해서 원하는 정보로 커스텀 해주고 이 메서드를 apiInfo의 인자로 호출하여 반환되는 ApiInfo 객체를 인자로 넘겨준다.
bean 객체에서 paths의 경우
.paths(PathSelectors.ant("/cloudvendor/*"))
이렇게 실행했을 때, 왜 get이랑 delete만 document에 뜨는지 모르겠다.
모두 띄우기 위해서 와일드카드로 *를 하나 더 붙여주었다.
(이유는 아직 모르겠음.)
내가 초기에 controller 클래스에서 각 mapping의 경로를 지정할 때 "/"를 붙이는 걸 빼먹어서 포함이 안되었던 것이다.
추가해주니, 위처럼 * 하나만 붙혀도 crud 모두 document 상에서 확인되었다.
실행하고 http://localhost:8080/swagger-ui/ 를 다시 접속하여 커스텀 되었는지 확인해보자.
우리가 ApiInfo에다가 설정해준대로, api document 제목도 Cloud Vendor API Application이라고 뜨며, 이 api가 cloud vendor api임을 더욱 이해할 수 있다.
또한 아래 파란색 글씨로, 나의 이름, wedsite, email 정보들이 있으며, license 정보도 잘 적혀있다.
website, email, license의 경우 누르면 해당 페이지로 이동할 수 있다.
또한 cloud vendor api만 문서화함으로써 아래 basic-error-controller도 제외된 것을 확인할 수 있다.
cloud vendor controller에 대한 모든 crud 메서드가 뜨는 것을 확인할 수 있다.
저안에서 직접 값을 입력하고 검색하며 api의 동작을 확인하고 이해할 수 있다.
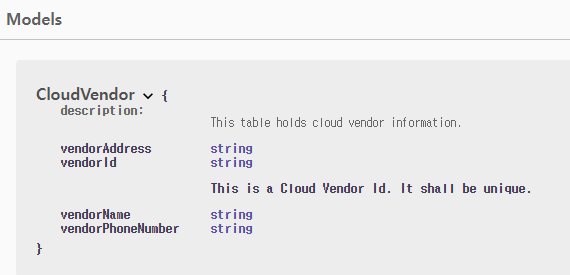
api 사용자가 이 swagger ui를 열어서 봤을 때 조금더 명확하게 정보를 이해하도록 할 수는 없을까??
특정 model의 어떤 속성은 무슨 속성을 말하는 걸까? 이런 디테일한 정보를 알려주기 위해서 좀 더 디테일하게 커스텀을 진행해보자. 필수는 아니지만, 이렇게 디테일하게 알려줌으로써 api 사용자에게 확실한 정보를 줄 수 있다.
이를 위해서 각 controller와 model의 속성 각각에 추가 정보를 담아서 document에 반영해보자.
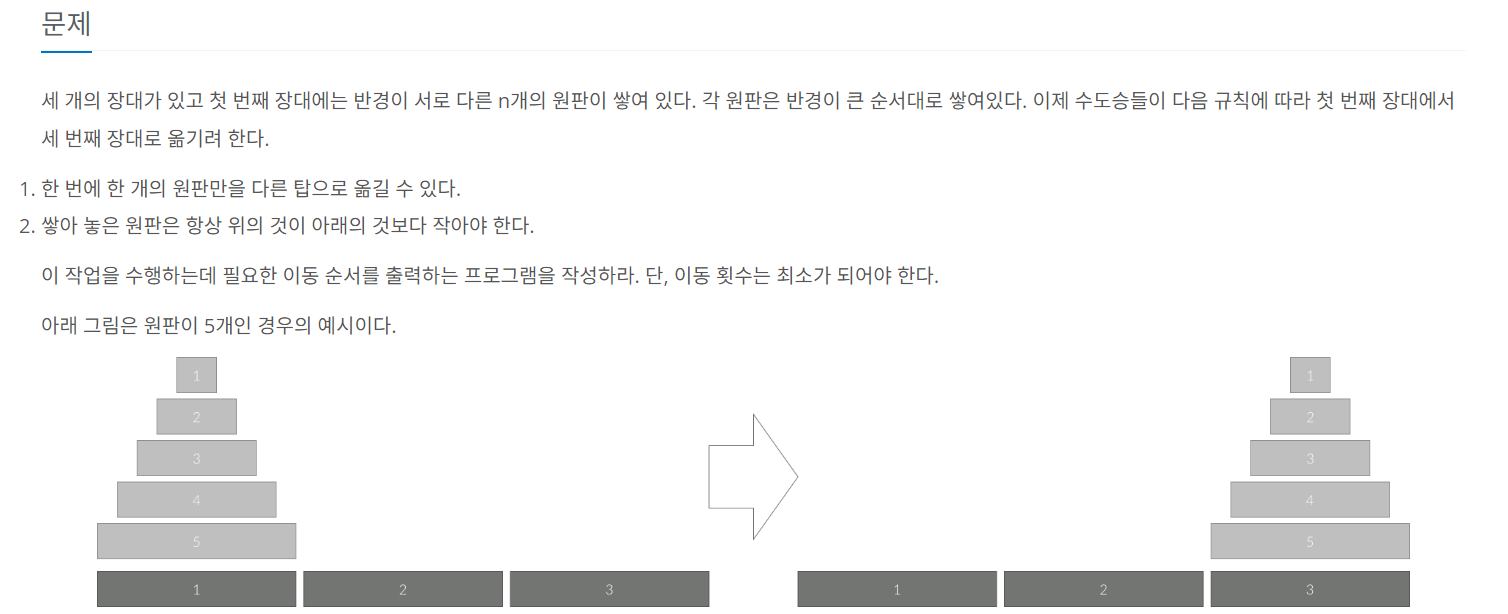
탑 1에 있는 가장 작은 원판을 탑 3으로 옮긴다. 탑 3에 있는 가장 작은 원판을 탑 2로 옮긴다. 탑 2에 있는 가장 작은 원판을 탑 1로 옮긴다. 탑 1에 있는 가장 작은 원판을 탑 3으로 옮긴다.
k-1개의 원판은 위 공식을 따르게 된다.
따라서 각 원판을 재귀 호출을 통해 이동 순서를 표현할 수 있다.
정리하자면, 1->3->2, 2->1->3 순서로 이동하게 된다.
이를 위해 hanoi라는 함수를 선언해준다.
이 함수는 현재 원판의 번호(=크기)와 시작(from), 중간(by), 끝(to) 지점을 인자로 갖는다. 만약 원판의 번호가 1이면 "from to"을 출력하도록 한다. 그렇지 않다면 hanoi를 호출하고 인자로 원판의 번호-1, from, to, by 순서로 넣어준다. 이는 1->3->2 순서를 나타낸 것이다. 그리고 이 함수를 호출한 후에는 "from to"를 호출하여 이동 상황을 출력한다. 그다음, hanoi를 한번 더 호출하여 인자로 원판의 번호-1, by, from, to 순서로 넣어준다. 이는 2->1->3 순서를 나타낸 것이다.
따라서 원판 하나에 대해 hanoi 함수는 두번 재귀호출 하므로, 연산이 2^k번 발생하는데, 가장 큰 원판은 바로 이동할 수 있으므로 1을 빼준다. 따라서 총 이동 횟수는 2^k-1이 된다.
참고로 c++의 경우, pow함수를 사용할 때 int로 형변환을 해주지 않으면 결과가 틀렸습니다가 나오므로, int로 꼭 변환한 후 -1을 빼주도록 한다. (pow함수의 반환 형태는 double 형이기 때문)
✏ 코드 전문
#include<iostream>#include<math.h>usingnamespace std;
voidhanoi(int n, int from, int by, int to){
if (n == 1) {
cout << from << " " << to << "\n";
}
else {
hanoi(n - 1, from, to, by);
cout << from << " " << to << "\n";
hanoi(n - 1, by, from, to);
}
}
intmain(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int k;
cin >> k;
cout << int(pow(2, k)) - 1 << "\n";
hanoi(k, 1, 2, 3);
return0;
}
queue를 사용하여 방문해야 할 곳을 pair<int,int> 형태의 좌표를 저장하도록 하였다.
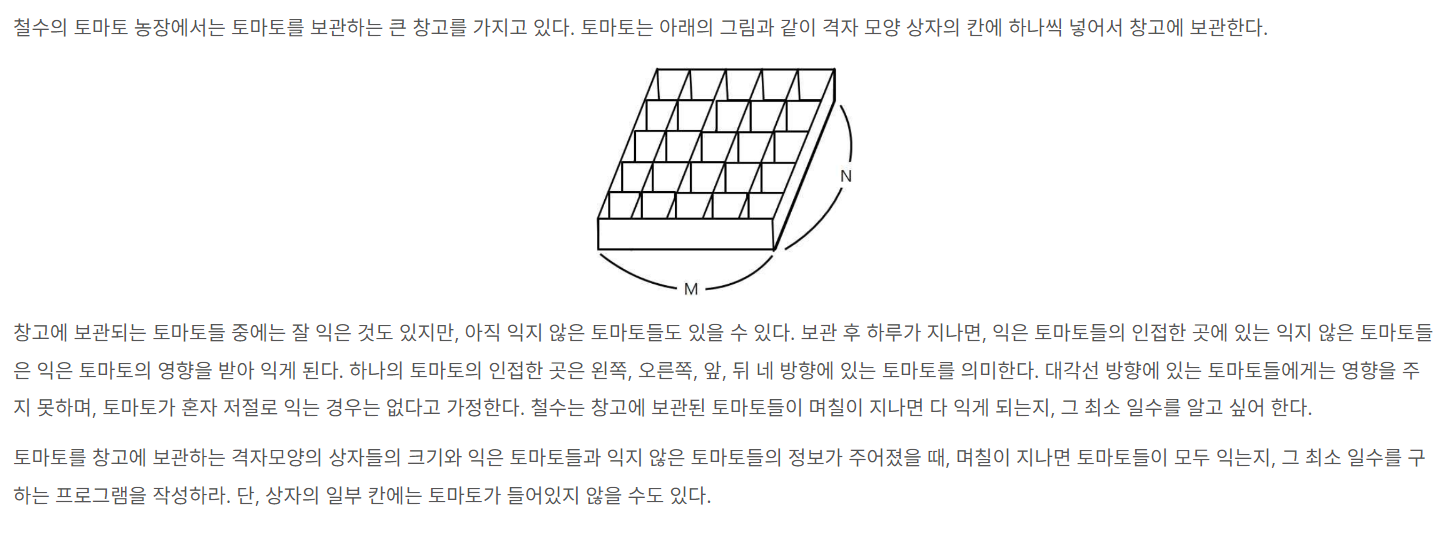
먼저 토마토에 대한 2차원 배열을 순회하면서 값이 1이면 그 위치를 q라는 queue에 pair<int,int> 형태로 넣는다.
모두 탐색한 후에는 while문으로 q가 빌때까지 bfs를 수행한다.
q에서 가장 앞에 있는 front의 first와, second를 bfs의 인자로 넘겨준다.
BFS함수의 동작 1. 인자로 받은 위치를 가지고, 동 서 남 북 방향에 있는 값이 배열의 인덱스 범위에 유효하며, 값이 0인지 확인한다. 2. 위의 조건을 만족한다면 해당 위치의 arr값을 1로 변경해주고, temp라는 이름의 queue에 해당 위치를 pair<int,int> 형태로 넣어준다.
BFS함수를 돌고 나면 q에서 pop한다.
그런다음, 현재 q가 비어있다면, 하루에 익을 수 있는 토마토는 다 익은 것이므로 하루를 카운트 하기 위해 answer를 1 증가시킨다.
새로 익어진 토마토에 대한 정보를 가진 temp 있는 위치 정보들을 q에 다 옮겨놓는다.
그리고나서 이어지는 다음 while문 동작부터는 다음 날짜에 대한 동작을 진행하는 것이다.
그런데, q가 비어지게 되면 temp가 비어있고, 그날이 마지막 날이었더라도 하루가 무조건 더해지게 되기 때문에, 마지막에는 answer에서 1을 뺀 값이 답이된다.
while문을 모두 수행하고 나면, 갱신된 2차원 배열을 순회하면서, 하나라도 0이 있는 값이 있는지 찾아본다.
이는 0이 하나라도 있다면 모든 토마토가 익어질 수 없다는 뜻이므로 -1을 출력하고 프로그램을 종료하기 위함이다.
그렇지 않다면 answer-1을 출력하도록 하여, 토마토 판에서 토마토가 다 익는데 걸리는 날을 출력한다.
✏ 코드 전문
#include<iostream>#include<vector>#include<queue>usingnamespace std;
int n, m;
vector<vector<int>> arr;
queue<pair<int, int>> q;
queue<pair<int, int>> temp;
int dx[] = { -1,1,0,0 };
int dy[] = { 0,0,-1,1 };
int answer = 0;
voidbfs(int x, int y){
for (int i = 0; i < 4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
if (nx >= 0 && nx < n&&ny >= 0 && ny < m&&arr[nx][ny] == 0) {
arr[nx][ny] = 1;
temp.push(pair<int, int>(nx, ny));
}
}
}
intmain(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cin >> m >> n;
arr.resize(n,vector<int>(m));
bool end = true;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> arr[i][j];
if (arr[i][j] == 1) {
q.push(pair<int,int>(i, j));
}
}
}
while (!q.empty()) {
bfs(q.front().first, q.front().second);
q.pop();
if (q.empty()) {//한번 돌았음을 의미
answer++;
while(!temp.empty()) {
q.push(pair<int,int>(temp.front().first, temp.front().second));
temp.pop();
}
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (arr[i][j] == 0) {
cout << -1;
return0;
}
}
}
cout << answer-1;
return0;
}
2022년 1월의 카테고리 별 도서 판매량을 합산하고, 카테고리(CATEGORY), 총 판매량(TOTAL_SALES) 리스트를 출력하는 SQL문을 작성해주세요. 결과는 카테고리명을 기준으로 오름차순 정렬해주세요.
✅ 문제 풀이
BOOK 테이블과 BOOK_SALES 테이블의 공통 속성인 BOOK_ID를 기준으로 INNER JOIN 해준다.
FROM BOOK A JOIN BOOK_SALES B ON A.BOOK_ID=B.BOOK_ID
이 중에서 판매 날짜인 SALES_DATE가 2022-01-01과 2022-01-31 안에 있는 것만 WHERE 절로 추린다.
WHERE B.SALES_DATE BETWEEN '2022-01-01' AND '2022-01-31'
카테고리 별로 묶어준다.
GROUP BY A.CATEGORY
문제에서 CATEGORY 당 판매량 총합을 구하라고 했으니, CATEGORY 별로 SALES의 SUM을 구한다. 이름은 TOTAL_SALES로 출력한다.
SELECT A.CATEGORY, SUM(B.SALES) AS TOTAL_SALES
조회결과를 CATEGORY에 대해 오름차순 정렬해준다.
ORDER BY CATEGORY;
✏ 코드 전문
SELECT A.CATEGORY, SUM(B.SALES) AS TOTAL_SALES
FROM BOOK A JOIN BOOK_SALES B ON A.BOOK_ID=B.BOOK_ID
WHERE B.SALES_DATE BETWEEN'2022-01-01'AND'2022-01-31'GROUPBY A.CATEGORY
ORDERBY CATEGORY;