DFS/BFS 알고리즘의 대표적인 문제 "타겟 넘버"의 풀이방법이다.
그 전에 DFS/BFS의 개념을 정리하자면,
그래프와 트리와 같은 자료 구조에서 사용되는 탐색 알고리즘이다.
문제에 따라서 각각의 접근방식을 달리 사용할 수 있다.
💡 DFS (깊이 우선 탐색)
- 깊이 우선 탐색은 한 분기를 끝까지 탐색한 후 다음 분기로 넘어가는 방식의 탐색 알고리즘이다.
- 시작 노드에서 출발하여 가능한 한 깊이 들어가면서 탐색한다.
- 주로 재귀 함수를 사용하여 구현하거나 스택(Stack)을 이용한다.
- 특정 경로를 탐색하다가 더 이상 진행할 수 없는 상황에 도달하면 이전 단계로 돌아와 다른 경로를 탐색한다.
- DFS는 그래프에서 사이클을 찾거나 깊이에 관한 문제를 해결하는 데 유용하다.
예시) 미로를 탐색할 때 한 방향으로 직진하다가 막히면 되돌아가서 다른 방향으로 계속 진행하는 방식이다.
💡 BFS (너비 우선 탐색)
- 너비 우선 탐색은 시작 노드에서부터 가까운 노드부터 차례대로 탐색하는 방식의 탐색 알고리즘이다.
- 큐(Queue) 자료 구조를 사용하여 구현한다.
- 주로 최단 경로를 찾는 문제에 사용되며, 모든 가까운 노드를 우선 탐색하여 최단 경로를 찾아낸다.
- BFS는 그래프에서 사이클을 찾지 않고, 가까운 노드를 먼저 탐색하는 데 적합하다.
예시) 같은 미로에서 모든 가로행을 먼저 탐색하고, 그 다음에 세로열을 탐색하는 방식이다.
결론적으로
DFS는 깊이 관련 문제를 해결할 때 유용하며, BFS는 최단 경로와 가까운 노드를 탐색할 때 효과적이다.
그럼 다시 본론으로 돌아와서...
해당 타겟 넘버 문제를 살펴보자.
문제에서는 주어지는 숫자 배열 numbers를 각각 더하거나 빼면서 target 값을 생성하는 방법을 반환하는 solution을 찾도록 되어있다.
그렇다면 numbers에 있는 숫자 개수 만큼 + 또는 -의 연산자가 필요하다.
모든 숫자 앞에는 + 또는 -의 연산을 해야하므로, 각각의 숫자는 + 또는 - 중에 선택되어야 하며, 트리 형태로 표현해보면 다음과 같이 표현할 수 있다.
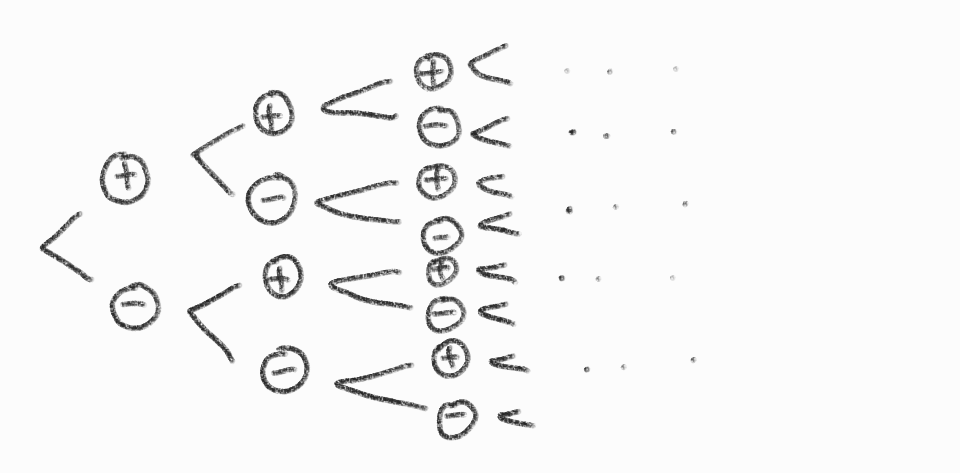
즉, 모든 경우의 수에 대해서 끝까지 탐색해 봐야 target 값이 도출되는지를 확인할 수 있다.
따라서 위 문제는 DFS로 해결할 수 있다.
DFS는 재귀 함수를 이용한다. 그럼 재귀함수를 어떻게 구성할 수 있을까?
한번의 연산에서는 +연산을 했을 때와 -연산을 했을 때의 두가지 경우를 고려할 수 있기 때문에, 두 연산을 각각 수행할 수 있도록 재귀함수를 사용해야 한다.
그런데, 마지막 노드에 대해서는 더이상 탐색할 것이 없기 때문에=해당 분기에 대해서는 다 탐색을 했기 때문에, 해당 연산이 target이 나오는지를 확인하고, 해당하면 이 분기는 타켓 넘버를 계산할 수 있는 경우의 수중 하나가 되기 때문에 1을 반환하도록 할 것이다.
따라서 solution이 시작될 때는 vector가 비어있는지부터 확인하여(비어있다면 다 탐색했다는 의미이므로), 비어있으면 return하는 동작을 수행하도록 한다.
그렇지 않다면 vector의 마지막 요소를 따로 저장해둔뒤, 해당 요소를 삭제한다.
그리고 solution함수를 호출해서 마지막 요속 삭제된 vector를 넘겨주고, target에 마지막 요소를 더한 값을 target자리로 같이 넘겨준다. 반환된 값을 answer에 저장되도록 한다.
이를 빼기 연산에 대해서도 동일하게 수행한다.
target에 vector의 마지막 요소를 더하거나 뺌으로써 탐색을 마쳤을 때 최종 target값이 0이 되면 해당 분기는 하나의 경우의 수가 되는 방식으로 생각했다. (=수학을 잘하자..)
그러면 최종적으로 answer에는 모든 경로를 탐색하여 얻은 "타겟 넘버를 만드는 경우의 수"를 저장하게 될 것이다.
코드는 아래와 같다.
int solution(vector<int> numbers, int target) {
if(numbers.empty()){
if(target==0) return 1;
else return 0;
}
int answer = 0;
int top = numbers.back();
numbers.pop_back();
answer+=solution(numbers, target+top);
answer+=solution(numbers, target-top);
return answer;
}
'CO-TE > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] JAVA / c++ LV2 전화번호 목록 / 해시알고리즘, SORT 풀이 (1) (1) | 2023.10.18 |
|---|---|
| [프로그래머스] MYSQL LV4 주문량이 많은 아이스크림들 조회하기 / UNION ALL 이용 (1) | 2023.10.18 |
| [프로그래머스] MYSQL LV2 조건에 맞는 도서와 저자 리스트 출력하기 / 풀이방법 (1) | 2023.10.17 |
| [프로그래머스] c++ LV2 택배 배달과 수거하기 (2023 KAKAO BLIND RECRUITMENT) 풀이/접근 방식 (0) | 2023.10.12 |
| [프로그래머스] c++ LV2 요격 시스템 풀이/접근방법 (0) | 2023.10.12 |


